5 Advanced Kubernetes Operators Every DevOps Engineer Should Know About
Introduction
Managing complex, distributed systems with Kubernetes can be challenging. That’s where Kubernetes Operators come in, automating and streamlining cluster management. But what exactly are operators, and why are advanced ones particularly useful?
Stay tuned for next part where we will dive deeper into creating our first operator.
Operators are custom controllers that extend Kubernetes capabilities, automating application management and ensuring your Kubernetes environment runs smoothly with minimal manual intervention. Advanced operators can handle complex tasks, making them essential for efficient cluster management.
“The operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides. Operators follow Kubernetes principles, notably the control loop.” — Kubernetes Documentation
In this blog, we will discuss operator pattern, the underlying Kubernetes primitives and look closer at 5 useful operators. If you are a DevOps or Platform Engineer, Kubernetes administrator or simply want to learn more about Kubernetes, this content is for you.
How Do Operators Work?
Kubernetes Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. They act as application-specific controllers, encoding operational knowledge and automating common tasks.
Operators follow a very important pattern in Kubernetes; declarative state reconciliation, which revolves around controllers continiously ensuring that the desired state expressed by a user matches the actual state reported by the resource. This process is called reconciliation.
Each operator consists of the following components.
- Custom Resource Definitions (CRDs) and Custom Resources (CRs).
- The Controller watches for changes in CRs and reconciles the state of the cluster accordingly.
- Resources represent the desired state of the resource.
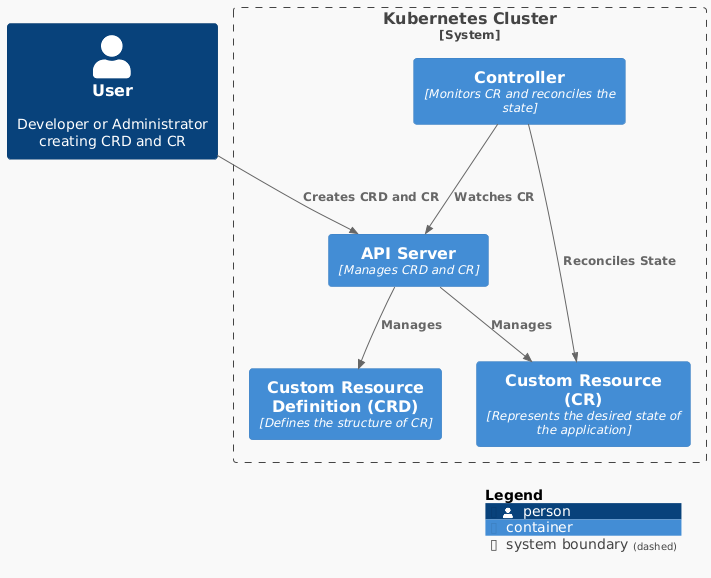
Learn more about operators in the Kubernetes Documentation
Operator Capability Levels
Operators come in various levels of sophistication. OperatorHub.io categorizes operators into five capability levels:
- Basic Install
- Seamless Upgrades
- Full Lifecycle
- Deep Insights
- Auto Pilot
As we move from Basic Install to Auto Pilot, operators become more advanced, offering increasingly sophisticated automation and management capabilities. In this post, we’ll focus on advanced operators at the higher end of this spectrum.
Why Advanced Operators Matter
Advanced operators (those at Full Lifecycle level and above) offer significant benefits:
- Automate sophisticated, application-specific workflows
- Implement best practices for scalability and high availability
- Reduce operational overhead and human error
- Enhance system reliability and performance
- Provide deep insights and auto-piloting capabilities for complex applications
If you ever had to deploy and manage infrastructure, especially in HA mode (high availability), you know how hard and error prone this process can be.
Advanced operators significantly reduce toil and complexity of infrastructure management. It’s like having a very capable but narrowly focused system administrator colleague that never sleeps and makes no mistakes.
Finding and Using Operators
A great resource for discovering and using Kubernetes Operators is OperatorHub.io. This repository hosts a wide variety of operators across all capability levels, allowing you to choose the right operator for your needs.
Let’s dive in and discover how these advanced operators can supercharge your Kubernetes environment!
Operator Lifecycle Manager
To make the installation process easier we are going to use operator lifecycle manager (OLM). The below command will install latest version of olm onto our cluster.
curl -sL https://github.com/operator-framework/operator-lifecycle-manager/releases/download/v0.28.0/install.sh | bash -s v0.28.0OLM streamlines the installation, management, and updating of operators in Kubernetes clusters. Key benefits include:
- Automatic Updates: Keeps operators up to date with over-the-air updates.
- Dependency Management: Ensures all necessary components are present and compatible.
- Discoverability: Makes it easy to find and use installed operators.
- Cluster Stability: Prevents conflicting operators from being installed.
- User-Friendly Interfaces: Provides intuitive UI controls for interacting with operators.
By using OLM, you can effectively manage the lifecycle of operators, ensuring a stable and efficient Kubernetes environment.
Now we are able to install various operators using the OLM CRDs.
You can try the code examples in online interactive Kubernetes environment
CloudNativePG Operator
The CloudNativePG Operator simplifies PostgreSQL management in Kubernetes. Here’s how it can help:
Key Benefits
- High Availability: Deploy multi-node PostgreSQL clusters with automatic failover.
- Scalability: Easily scale PostgreSQL resources up or down based on demand.
- Automated Backups: Set up scheduled backups and streamline the recovery process.
Use Cases
- High Availability PostgreSQL Clusters
- Database-as-a-Service for Development Teams
- Consistent Database Deployments Across Environments
Installation
To install the CloudNativePG operator:
Let’s verify if the pg operator was installed by listing the csvs (ClusterServiceVersions) in the default namespace:
kubectl get csv
NAME DISPLAY VERSION REPLACES PHASE
cloudnative-pg.v1.23.2 CloudNativePG 1.23.2 cloudnative-pg.v1.23.1 Succeeded1. Deploy a Basic PostgreSQL Cluster
echo "
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: pgcluster-sample
spec:
instances: 3
storage:
size: 1Gi
" | kubectl apply -f -2. Configure Backup
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: pgcluster-with-backup
spec:
instances: 3
storage:
size: 1Gi
backup:
barmanObjectStore:
destinationPath: "s3://my-bucket/backup"
s3Credentials:
accessKeyId:
name: aws-creds
key: ACCESS_KEY_ID
secretAccessKey:
name: aws-creds
key: ACCESS_SECRET_KEY
retentionPolicy: "30d"This configuration sets up automated backups to an S3 bucket, retaining backups for 30 days.
3. Scale the Cluster
To scale the cluster, simply update the instances field in your cluster definition:
echo "
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: pgcluster-sample
spec:
instances: 5 # Increased from 3 to 5
storage:
size: 1Gi
" | kubectl apply -f -The CloudNativePG operator will automatically handle the scaling process, adding new instances and reconfigurating the cluster for high availability.
These examples illustrate the capabilities of operators in managing SQL databases within Kubernetes environments. The CloudNativePG operator, specifically designed for PostgreSQL, simplifies a wide range of database management tasks. From basic deployments to advanced configurations for backups and scaling, it provides a seamless experience. This demonstrates the potential of using operators for SQL databases, where PostgreSQL is just one example. With operators, complex database operations become manageable and efficient, highlighting their value in modern database administration.
Jaeger Operator
The Jaeger Operator simplifies the deployment and configuration of Jaeger, an open-source distributed tracing system. Here’s how it can help:
Key Benefits
- Distributed Context Propagation: Trace requests across microservices to identify performance issues.
- Service Dependency Analysis: Visualize service dependencies to understand interactions.
- Root Cause Analysis: Quickly identify the root cause of performance bottlenecks.
Use Cases
- Microservices Monitoring
- Performance Optimization
- Debugging Distributed Systems
Installation
To install the Jaeger Operator:
kubectl apply -f https://operatorhub.io/install/jaeger.yamlUsage Example
Here’s a representative example of deploying a production-ready Jaeger instance:
kubectl apply -f - <<EOF
apiVersion: jaegertracing.io/v1
kind: Jaeger
metadata:
name: jaeger-production
spec:
strategy: production
storage:
type: elasticsearch
elasticsearch:
nodeCount: 3
resources:
requests:
cpu: 1
memory: 2Gi
limits:
memory: 2Gi
ingress:
enabled: true
agent:
strategy: DaemonSet
sampling:
options:
default_strategy:
type: probabilistic
param: 0.1
EOFThis example demonstrates how operators streamline the deployment of distributed tracing solutions in Kubernetes. The Jaeger Operator, in particular, allows for the deployment of a fully-featured, production-ready Jaeger instance with a single custom resource definition. This showcases the operator’s power in simplifying complex distributed tracing setups, making it easier to monitor and analyze microservices environments efficiently. The Jaeger Operator exemplifies how operators can significantly reduce the complexity of managing distributed tracing tools in Kubernetes.
Argo CD Operator
The Argo CD Operator manages the lifecycle of Argo CD, a declarative, GitOps continuous delivery tool for Kubernetes. Here’s how it can help:
Key Benefits
- GitOps Deployment: Automate deployments directly from Git repositories.
- Lifecycle Management: Handle upgrades, backups, and restores of Argo CD instances.
- Monitoring and Insights: Integrated monitoring with Prometheus and Grafana.
Use Cases
- Automated GitOps Workflows
- Multi-Tenant Argo CD Management
- Scalability and High Availability
Installation
To install the Argo CD Operator:
kubectl apply -f https://operatorhub.io/install/argocd-operator.yamlThis installs the Argo CD Operator in the argocd-operator-system namespace.
Usage Examples
1. Deploy a Basic Argo CD Instance
kubectl apply -f - <<EOF
apiVersion: argoproj.io/v1alpha1
kind: ArgoCD
metadata:
name: example-argocd
spec: {}
EOF2. Configure Backup for Argo CD
kubectl apply -f - <<EOF
apiVersion: argoproj.io/v1alpha1
kind: ArgoCDExport
metadata:
name: example-argocdexport
spec:
argocd: example-argocd
schedule: "0 * * * *"
storage:
backend: aws
secretName: aws-secrets
EOFThis example demonstrates how operators enhance GitOps workflows in Kubernetes environments. The ArgoCD Operator enables the deployment of a fully-functional, production-ready ArgoCD instance with just a single custom resource definition. This highlights the operator’s effectiveness in simplifying GitOps setups, allowing for continuous deployment and version control directly from a Git repository. The ArgoCD Operator exemplifies how operators can streamline and automate the management of GitOps tools in Kubernetes, ensuring more efficient and reliable application delivery.
Prometheus Operator
The Prometheus Operator simplifies the deployment and management of Prometheus monitoring instances. Here’s how it can help:
Key Benefits
- Automated Monitoring Setup: Easily deploy Prometheus instances for specific namespaces, applications, or teams.
- Dynamic Service Discovery: Automatically generate monitoring targets based on Kubernetes labels.
- High Availability Monitoring: Deploy multiple Prometheus instances across failure zones with data replication.
Use Cases
- Automated Monitoring Setup
- Dynamic Service Discovery
- High Availability and Custom Alerting
Installation
To install the Prometheus Operator:
kubectl apply -f https://operatorhub.io/install/prometheus.yamlThis installs the Prometheus Operator along with a complete monitoring stack including Prometheus, Alertmanager, and Grafana in the monitoring namespace.
Usage Examples
1. Deploy a Prometheus Instance
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
ruleSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
EOFThis creates a Prometheus instance that will monitor services labeled with team: frontend.
2. Set Up Service Monitoring
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
EOFThis ServiceMonitor will discover and monitor all services labeled with app: example-app.
3. Create Alerting Rules
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: example-alert
labels:
team: frontend
spec:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="example-app"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency for example-app
EOFThis rule will trigger an alert when the request latency for example-app exceeds 0.5 seconds for 10 minutes.
4. Configure Alertmanager
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
spec:
replicas: 3
EOFThis creates an Alertmanager cluster with 3 replicas for high availability.
5. Set Up a PodMonitor
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: example-pod
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-pod
podMetricsEndpoints:
- port: metrics
EOFThis PodMonitor will discover and scrape metrics from pods labeled with app: example-pod.
6. Configure Thanos for Long-Term Storage
kubectl apply -f - <<EOF
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
thanos:
baseImage: quay.io/thanos/thanos
version: v0.22.0
storage:
volumeClaimTemplate:
spec:
storageClassName: standard
resources:
requests:
storage: 100Gi
EOFThis configuration sets up Prometheus with Thanos sidecar for long-term metric storage and querying across multiple Prometheus instances.
The Prometheus Operator streamlines Prometheus deployments in Kubernetes environments, offering both simplicity and advanced functionality. It efficiently handles basic setups while supporting sophisticated configurations like high availability, customized alerting, and long-term data retention. By automating complex monitoring tasks, the operator allows teams to focus on deriving valuable insights from their Kubernetes infrastructure, significantly reducing operational overhead.
Strimzi Operator for Apache Kafka
The Strimzi Operator provides a way to run and manage Apache Kafka clusters on Kubernetes or OpenShift in various deployment configurations. Here’s how it can help:
Key Benefits
- Kafka Cluster Management: Deploy and manage Kafka clusters with ease.
- Data Streaming Platform: Integrate Kafka Connect for seamless data integration.
- Multi-Cluster Replication: Use Kafka Mirror Maker for data replication across clusters.
Use Cases
- Kafka Cluster Management
- Data Streaming Platform
- Multi-Cluster Replication
Installation
To install the Strimzi Operator:
kubectl apply -f https://operatorhub.io/install/strimzi-kafka-operator.yamlThis installs the latest version of the Strimzi Operator in your Kubernetes cluster.
Usage Examples
1. Deploy a Kafka Cluster
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.7.1
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}This example deploys a Kafka cluster with 3 brokers and 3 ZooKeeper nodes, using JBOD storage for Kafka.
2. Create a Kafka Topic
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 10
replicas: 3
config:
retention.ms: 7200000
segment.bytes: 1073741824This creates a Kafka topic with 10 partitions and 3 replicas.
3. Set Up Kafka Connect
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
annotations:
strimzi.io/use-connector-resources: "true"
spec:
version: 3.7.1
replicas: 3
bootstrapServers: my-cluster-kafka-bootstrap:9092
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-statusThis deploys a Kafka Connect cluster with 3 replicas.
These examples demonstrate how operators streamline distributed messaging systems within Kubernetes environments. The Strimzi Operator manages Kafka ecosystems efficiently, handling tasks such as deploying Kafka clusters, setting up data replication, and enabling advanced features like automatic rebalancing. By simplifying these complex operations, the Strimzi Operator enhances the management of Kafka in cloud-native settings, highlighting its effectiveness in distributed messaging.
Closing Thoughts
The pattern we’ve been applying continiously is at the core of Kubernetes declarative resources management. We have been declaring the desired state of our resources using Kubernetes CRD (Custom Resource Definition) extensibility model that is at the heart of the operator pattern. You can think of it as instructing actual operator to perform certain tasks; backups, configrutaion, upgrades etc. We were able to achieve all this using declarative approach focusing on what needs to happen but not how exactly it needs to happen.
Looking to the future, we can expect Operators to become even more sophisticated. Improved AI/ML capabilities for predictive scaling and self-healing, and expanded coverage for emerging technologies and cloud-native patterns. As the ecosystem matures, we’re likely to see greater standardization in Operator development practices and APIs.
Thanks for taking the time to read this post. I hope you found it interesting and informative.
🔗 Connect with me on LinkedIn
🌐 Visit my Website
📺 Subscribe to my YouTube Channel